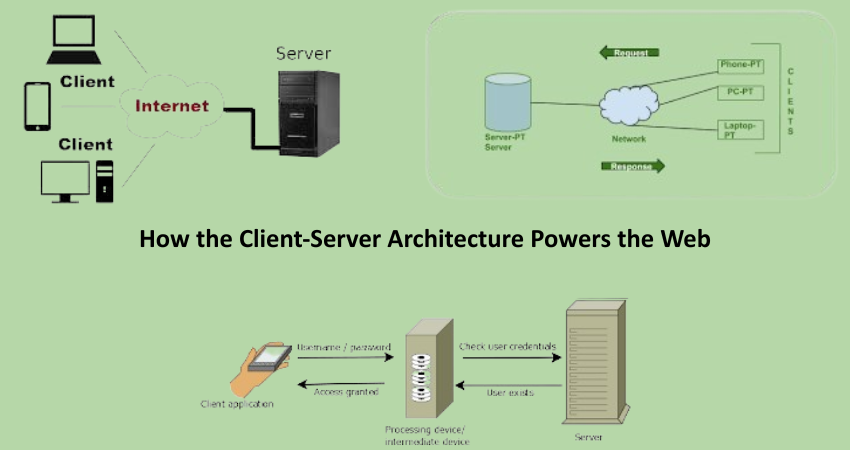
Understanding the Basics of Client-Server Architecture
What Is Client-Server Architecture?
Client-server architecture is the hallmark of computer networking. They are servers and clients, respectively, in the role of processor or computer. The client, typically, is the device or software that makes requests, while the server is that massive computer or software that services those requests, rendering services or resources. The model is fundamental for the way we all know the internet. Every time a person browses a website, checks e-mail, or downloads a video, they engage in client-server architecture.
The client-server model communicates through clear protocols and standards and is especially popular for that involving, most of the time, HTTP for web browsers to communicate with web servers. An architecture of this type provides scalability, modularity, and manageability. The client can be anything from a web browser to a mobile app to even complex enterprise applications, while servers take care of data storage, application logic, and user authentication. The separation introduces efficiencies and enhances security and performance by localizing critical tasks to dedicated systems.
How the Model Works in Practice
The request for the server is made by your browser whenever you input a URL into the browser. The request subsequently gets processed at the server, which is often found in a data center elsewhere, and the required page or data is then sent back. Yes, this generally happens in milliseconds and is continued repeatable when the users navigate through pages, submit forms, or interact with service portals. It just happens seamlessly, as though really no other activity is occurring among the users. However, it has quite a complex interaction, including things such as DNS resolution, packet routing, and data rendering.
It’s this capability that allows handling requests from a few clients to be spread over several hundred of them in regards to client-server design. Indeed, the web servers can easily accommodate thousands of concurrent connections and still answer each client in a timely manner. This is true even if there exist server clusters and load balancers relaying traffic to ensure high availability. It no longer allows the programmers to work on the same applications using server-based models, yet it allows the developers to modify certain applications on the server side while leaving client front end work unchanged.
Key Components of Client-Server Architecture
The Role of Clients in the Network
In the case of networked applications and services, clients would serve as the front ends with which users interact. Within the Web world, a client would be a web browser or mobile app that initiates communication with a server to receive or send data. Clients render data in a way that is easy to understand by users and capture user input in such a way that it can be further processed. These units thus are often running on less-powerful devices such as personal computer workstations versus smartphones, tablets, and so on, with the heavier lifting such as database queries or complex business logic computations performed on remote servers.
Client applications are becoming a lot richer and complex nowadays, with powerful user interfaces and interactive elements being enabled through JavaScript frameworks like React, Angular, or Vue.js. The rational consequence of these developments has led to an active change in the role of clients from passive data receivers to active participants in the computing process. But these modern applications that empower clients are still heavily reliant on servers that access shared resources, maintain session states, and protect data transactions. This symbiotic relationship also guarantees client responsiveness, scalability, and security.
Server Functions and Responsibilities
Servers are the backbone of the client-server model, carrying out the heavy lifters of betwixt things like hosting websites, saving databases, running applications, and managing user identities. They take care of the major tasks that a client would end up doing by itself. A web server delivers HTML, CSS, and JavaScript files to the customers, while an application server processes the logic and database. Servers come with heavy-duty hardware, along software, to deliver optimal performance, reliability, and security.
Besides serving the requests from client computers, servers also maintain a log of requests made by clients, formulate some security protocols, and would also do routine maintenance, such as software upgrades and backups of data. They operate in the most conducive environment: a vast ecosystem of firewall, load balancer, and monitoring systems. It is simple for a server to keep track of easier storage, frequent up-dating, and controlled access. This is also a general, more specific way to engage the preservation of security and data integrity alongside compliance with regulations and the stability of overall web applications.
The Importance of Protocols in Client-Server Communication
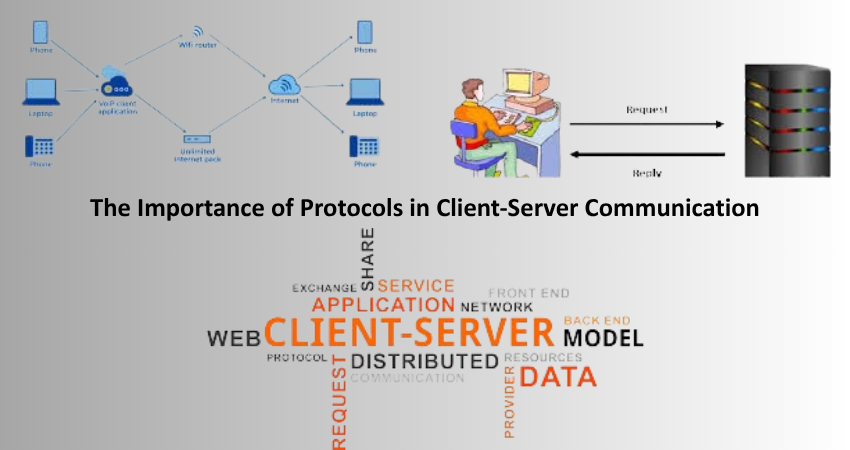
HTTP and HTTPS: The Web’s Lifeline
Somewhat at depth, the Hypertext Transfer Protocol (HTTP), being the main protocol used in the client-server model, takes on the responsibility of communicating intermediate messages between the browser and the servers. It determines how messages are formatted and transmitted, and what actions are to be taken by servers and browsers in response to various commands. When you access a website, an HTTP request is sent by the browser and acted upon by a server, sending back the resources requested. Thus, from the very beginning, supplying web pages, images, videos, and other types of content on the Internet is dependent on this procedure.
An extension of HTTP from the beginning with a layer of encryption provided above by SSL/TLS is HTTPS (which you may have heard as ‘HTTP Secure’). So, such an added layer of security ensures that any data exchanged between the client and server is encrypted, which stops any malevolent attack from intercepting or tampering with that data. Indeed, HTTPS has become the gold standard in the web today, especially for websites that deal with sensitive user information like login credentials, payment information, or other personal details. Using HTTPS is not just best practice; it has become a necessity for modern web apps that care for their users’ trust and the protection of their data.
Other Vital Protocols: FTP, SMTP, and DNS
To say HTTP and HTTPS are the most common protocols, some others also play significant roles in providing an array of web functionalities. FTP or File Transfer Protocol is the protocol that transfers files from clients to servers for web-uploading assets or downloading large datasets. Almost all FTP servers have an interface that allows users to interact with remote servers for the management of files and directories. It is one of the very few applications that a developer or site administrator would have to use.
SMTP or Simple Mail Transfer Protocol sends email messages from a client application to a mail server. SMTP works with other protocols such as IMAP and POP3, which allow the retrieval of messages from a server. The Domain Name System (DNS) is another important protocol that converts human-readable domain names into machine-readable IP addresses. When you enter a URL in your browser, DNS resolves it to direct your request to the correct server address. These protocols together make up the client-server communication backbones that allow various services we depend on daily.
Scalability and Performance in Client-Server Architecture
Load Balancing and Redundancy
In the client-server architecture, particularly on the web application side where it needs to cater for a lot of users, scalability is one of the fundamental principles. Load balancing is defined as a process of distributing incoming requests from clients across multiple servers so that no one server is overloaded. Apart from enhancing server capacities, load balancing will also improve reliability since the likelihood that a single server will fail decreases. Load balancers are either hardware-based or software-based, and most of them use some algorithm, such as round-robin, least connections, or IP hash, to determine how traffic will be routed.
Another major element for high availability and fault tolerance is redundancy. It helps in implementing the logic that if one of the servers goes down, the application can survive as long as the other one or more servers with the same capability keep running. Redundancy can be introduced in many ways such as clustering or via cloud services that resource dynamically following demand. A redundant system can also be maintained or upgraded while the active system still serves clients. Coupled with a load balancer, redundancy constructs a very reliable client-server architecture that can altitudinously scale under varying loads.
Caching and Content Delivery Networks (CDNs)
Caching is a technique used to store copies of frequently accessed information in temporary storage to reduce the waiting time and server stress. In a client-server architecture, caching may occur at several points in the system, from client-side (browser cache) to server-side (application cache) to intermediate proxy servers. High-speed serving of cached content enables the system to respond to requests quickly, therefore reducing latency and improving user experience.
Caching is taken to an advanced stage by a Content Delivery Network (CDN). This happens when very many geographically separate servers join hands to create a network of CDNs. That way, when a client tries to obtain a file, the CDN immediately serves the file from one of the geographically-nearest servers to that user, thereby reducing latencies and speeding up load times. It is true that CDNs are most helpful in delivering static assets such as images, videos, and stylesheets, but there are certain instances where they employ dynamic assets as well. CDNs also increase the scalability of sites by offloading traffic from the origin servers while reducing bandwidth costs and enhancing global accessibility. Thus, they are one of the critical and inevitable components of modern client-server architectures.
Security Considerations in Client-Server Architecture
Common Threats and Attack Vectors
The client-server paradigm is very efficient yet very vulnerable to security threats. Just to skim through a few common attack vectors: between the communicating parties, that is, the client’s end and the server’s end, the exchange can be interrupted by the adversary to perform an MITM (man-in-the-middle) attack; on the other hand, a SQL injection attack is one of the most common that can be performed by inserting malicious code into queries that ultimately manipulates the database. Cross-site scripting (XSS) is another rampant threat that characterizes scripts running on the client’s side to execute unauthorized commands. Such vulnerabilities can lead to breaches of data, disruptions of service, or reputational harm to the victimized organizations.
A layered approach to security must be adopted in order to mitigate such risks. Among them are secure protocols (HTTPS), user input validation and sanitization, firewall, intrusion detection systems, etc. Security audits serve as well periodic vulnerability assessments that can be implemented to discover and fix security weaknesses. Security threats can also proactively manage organizations keeping their systems and users safe from harm, thus promoting web application integrity and trustworthiness as far as possible.
Authentication and Access Control
The above systems comprise efficient security components that authenticate users but, unlike authentication, access control determines what resources and actions authenticated users may access and execute. The systems perform an important role for security within the client-server environment as it restricts access to sensitive data and functionalities by authorized personnel. Typically, authentication is achieved using one or more of the above means: username-password combinations, multi-factor authentication (MFA), and token systems such as OAuth and JWT.
Access control generally entails role-based access control (RBAC). This assigns permissions based on roles of users; and attribute-based access control (ABAC), which utilizes many attributes and conditions in determining access. These are, however, minimum-privilege systems in that they ultimately ensure that users are assigned the minimum level of access necessary to complete their task. Therefore, centralized servers of authentication and directory services subsequently enhance the identity management process by ensuring a consistent, secure application of access control throughout the network-for example, LDAP and Active Directory. For client-server architecture, the basis of functioning and security builds a strong dependence on authentication and access control.
The Future of Client-Server Architecture
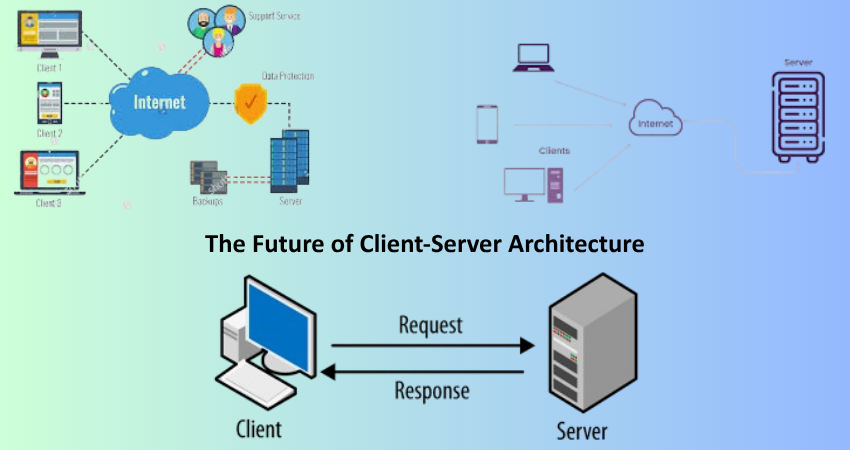
Evolving Technologies and Trends
Like all other technologies, the client-server architecture evolves and adapts according to new technologies and changing user needs. One major trend has been to take applications toward microservices; this style of application architecture is the fragmentation of a larger application into much smaller mostly independent functions that communicate through APIs. This brings great improvement in scalability, flexibility, and maintainability since team members can develop, deploy, and scale their components without affecting the entire system. Microservices mostly deploy and put services within a containerized environment using tools like Docker and then orchestrate them with tools such as Kubernetes.
On the other hand, there is emerging technology that is transforming server-based applications by bringing with them artificial intelligence (AI) and machine learning (ML) qualities. They fuel revolutionized real-time data analyses, customized user experiences, and smart automation. As edge computing catches on, processing is done nearer to the client because some of it is handled in edge servers, as shown in table-latency improvements with 30-50 percent fastest response rates. These distributed and intelligent architectures-without losing touch with the core principles of the client-server model-are indicative of a changing trend.
Client-Server in the Age of Cloud Computing
Cloud computing has transformed client-server architecture to provide on-demand access to computing resources over the internet. Thus, Amazon Web Services (AWS) and Azure, and Google Cloud provide scalable infrastructure, storage, and services provisioned and managed remotely, hence allowing organizations to more rapidly, flexibly, and cost-efficiently deploy client-server applications.
In short, “cloud computing” refers to the fact that a server is not always really a physical machine housed in a far-off data center. It can be a virtual instance that can be increased dynamically over application demands. This essentially allows resources to be used in the most efficient manner as well as having them highly available. They also provide managed services, for example, in databases, authentication, and content delivery-and that also saves developers and administrators from lots of operational burdens. Cloud computing has reinforced client-server architecture, but also presents new opportunities for innovations and growths as it gains momentum in further utility.
Conclusion
As the technology of cloud computing progresses, it becomes a more dynamic and resource-efficient model of client-server interaction. Among the managed services the cloud offers today are serverless computing, container orchestration, and auto-scaling—all of which abstract from the complexity of traditional server management. Such innovations allow developers to actually concentrate on building sound applications while not worrying about provisioning or maintaining any sort of physical infrastructure. Moreover, with the cloud providers having global data centers and an increasingly advanced networking capability, they guarantee high availability and low latency for users all over the world. Such a convergence of client-server principles and cloud-native strategies bolsters flexibility, lowers costs, and hastens innovation.
Along the same lines, client-server architectures remain the backbone of all the modern web technologies, from the simplest of websites to the most convoluted enterprise applications. Attention-grabbing as it is from the point of separation of concerns, scalability, and its long list of protocols, it stands the test of time. With new technologies like microservices, edge computing, and AI making adjustments and expirations in future timeframes, this same paradigm will flex and fuse as the world represents a closer user with a seamless, secure, scalable web experience. Thus, understanding this architecture will be of utmost significance for one to get a grasp of how things work over the web and what they are becoming in the years ahead.