
Introduction
Node.js is well known for its event-driven and non-blocking I/O model, making it a lightweight and efficient platform for creating scale-up network applications. However, because it is inherently single-threaded, node applications sometimes have to deal with CPU-intensive tasks and massive workloads. This is where the Cluster module comes to the fore. It solves the problem by allowing the application to create child processes and utilize the server ports via them, hence taking maximum advantage of multi-core systems and improving performance.
This article will serve you with information about the Cluster module – what it is, how it works, how to set it up, and what are the benefits and drawbacks. This no-holds-barred guide suits those developers who are eager to harness their Node.js applications severely and optimally from the hardware.
What is the Cluster Module in Node.js?
Single-threaded Limitations and the Need for Clustering
Node.js employs a single-threaded event loop design that makes it quite appropriate for handling I/O operations. But this architecture lays definite constraints on using CPU-bound operations or handling numerous concurrent requests at a time. This means that, when a CPU-intensive task is performed by a Node.js application, the resulting effect would be blocking the event loop, leading to performance bottlenecks and increased degradation of user experience. In particular, this limitation is prominent in production environments where it would be taken for granted that high speed and availability would be required.
One of the solutions to the limitation was the Cluster Module, which provided the possibility of starting several Node.js processes at once. These processes, called “workers,” would accept and work on requests independently, fully leveraging the power of modern multi-core systems. Each worker is practically an independent Node.js application instance having its own event loop and memory space under the control of the master process. Thus, if one worker crashes, all the remaining workers continue to function, thereby impeding the resilience and fault tolerance of the application.
Core Concepts and Process Management
In this sense, the master-worker model is basically the focal point of the Cluster module. A master process forks worker processes and raises the status of those workers to the master, but the master does not accept any incoming HTTP calls. Rather, incoming requests are connected up with the worker processes and distributed for processing. Workers are forked from the cluster using the cluster.fork() method; each worker runs a separate instance of the server logic defined in your code.
Communication between workers and the master process is done through the inter-process communication (IPC) channel, which is set up automatically when the workers are forked. The master receives status updates and error messages from the workers via this communication. The master is also able to issue commands to the worker, such as restarting that particular worker or broadcasting messages to it. This is a very good basis for developing strong, scalable Node.js applications that can, if if a worker becomes unavailable, restart itself.
How the Cluster Module Works
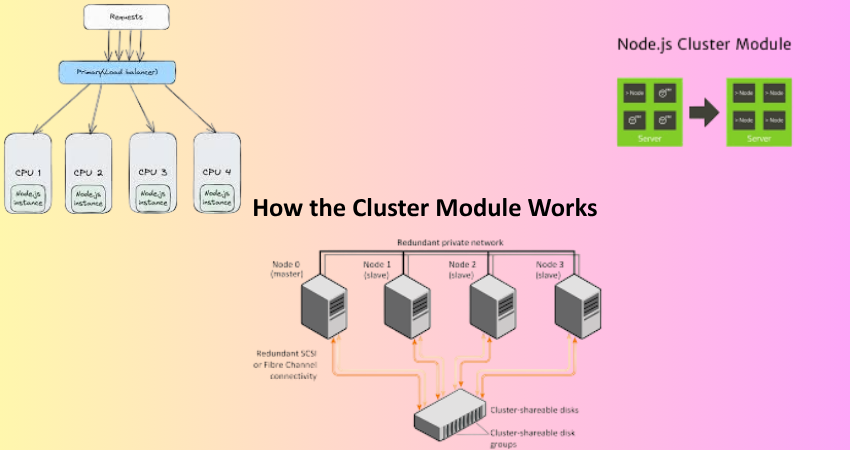
Master and Worker Lifecycle
In case of Cluster module for Node.js applications, the original script runs in master context. The master process then forks one or more worker processes through cluster.fork(). Each such worker will run the same script but will have its independent execution context. Thus, memory is not shared among them, but they may communicate with the master process and each other through IPC.
Thanks to the master process directing socket connections, each worker process listens on the same server port. Thus, the design allows the master process to seamlessly load balance the incoming client requests among the available workers, which is often done via a round-robin algorithm on Unix-like platforms. Distributing the load among many workers can tremendously improve an application’s ability to handle simultaneous requests, thereby enhancing the performance and user experience.
Inter-process Communication and Load Balancing
The most important thing about the Cluster module is that it has an inbuilt IPC for the communication between master and workers, allowing control flows and health monitoring along with message exchanges. For example, heartbeat messages from workers signal the master when they are alive and the master is notified when a worker finds errors. So the master can automatically restart unresponsive or failed workers, leaving the application steady.
As far as load balancing is concerned, the operating system or Node.js runtime takes care of distributing network connections over worker processes. In Unix systems, the incoming connections are distributed to the master using a round-robin technique. In Windows, the responsibility for accepting a new connection is up to the workers. But of any OS, the outcome will be – every request will be evenly distributed, allowing the application to leverage all CPU cores and minimize latencies at high loads.
Setting Up a Cluster in Node.js
Basic Cluster Implementation Example
Once the cluster module needs to be implemented in a Node.js application, it requires the cluster module as well as the os module to find out how many CPU cores are available, following which it checks if the running process is the master or one of the workers using cluster.isMaster. If it is the master, it calls cluster.fork() to create workers equal to the number of CPU cores. If it is a worker, an HTTP server or application logic will be started.
An example:
const cluster = require(‘cluster’);
const http = require(‘http’);
const os = require(‘os’);
const numCPUs = os.cpus().length;
if (cluster.isMaster) {
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on(‘exit’, (worker) => {
console.log(`Worker ${worker.process.pid} died. Spawning a new one.`);
cluster.fork();
});
} else {
http.createServer((req, res) => {
res.writeHead(200);
res.end(`Hello from worker ${process.pid}`);
}).listen(8000);
}
Production Readiness and Graceful Shutdowns
It is quite easy to set up a test cluster, but deploying one in production is an altogether different ballpark. Handle unexpected errors gracefully; centralize logs so they can be monitored; have an appropriate shutdown procedure to prevent data loss and allow smooth restarts. Listening for system signals like SIGTERM or SIGINT before exiting the process by terminating all connections to the server is a common practice.
Worker health and memory utilization are also monitored. If one exceeds the threshold limit defined for it or fails to respond, the master process would kill and restart it. You can use PM2 or Forever for the management of this process, offering extensive monitoring, logging, and automatic process restarting. With these practices, your application will continue to behave as intended under different conditions: loads and errors.
Advantages of Using the Cluster Module
Performance Gains and Scalability
The cluster module is mostly used for improving performance through the proper utilization of multiple cores. This means that the Node.js application can run more concurrent requests because the multiple worker processes will more probably parallelize those more CPU-intensive tasks across different cores rather than a single core, leading to better resource usage, faster response time, and more scaling application that can grow along with your user base.
Real-world clustered applications can achieve significant latency and error reduction under high load conditions. For example, the many tasks that an API server has to perform handle thousands of requests per second and tend to get distributed through several cores, even during the pike times. This makes clustering a very important concept for modern web applications, microservices, and APIs.
Fault Tolerance and High Availability
Clustering also lends to the reliability of your application. If, by chance, an unhandled exception, or memory leak, causes a worker process to crash, the master process can spawn a new worker to carry on the load. These self-healing mechanisms are vital so that the application can keep functioning unattended, thus improving the uptime and availability.
Additionally, worker isolation protects the application from being affected by any single point of failure. Each worker runs in its own memory space, so that crashes and bugs do not leave their space. Along with logging and monitoring, this setup allows developers to pinpoint issues with speed and fix them without impacting users’ experience. Thus, high availability and resilience are important. The Cluster module offers a solid platform to achieve these things.
Conclusion
The Cluster module in Node.js provided a remedy to single-threaded shortcomings via multi-core utilization and applications scalability. Understanding master-worker architectures, inter-process communication, and their implementation practicals will empower a developer to build resilient and high-performance Node.js applications with production-scale workloads.
Be it online activity or RESTful APIs, or a heavy computational service, incorporation of the Cluster module within the architecture is a big improvement in achieving even higher efficiency and reliability. The proper setting and monitoring will switch your lightweight prototype Node.js app into a robust and scalable enterprise application.