
Introduction
A good solid database is the backbone of a scalable application that performs well and keeps the data intact. At the centre is the database schema, which is a blueprint of how the data is organized, stored, and related to the other data within that system. Whether you are building a blog, an e-commerce store, or even a social media application, an understanding of basic database schema design will be fundamental to the effectiveness of its back-end systems. Yet, it is still common for a lot of developers to just dive in and start coding with little or no attention paid to the thinking and organizing around underlying data structure, and later, they run into problems that could easily have been avoided with a little advanced planning.
Determining the database schema is more than just building tables; it is about defining all the relationships between data entities as well as ensuring that the application works with data consistent across its various sources. A good schema allows for fast queries, eliminates redundancies, and provides support for application logic without encumbrances. A web developer who understands these concepts would not only be able to build stable applications but also be an effective collaborator with all the various disciplines within the development team, from data engineers to front-end developers. This guide seeks to define the core concepts of database schema design, best practices, and common pitfalls, thus providing tools for web developers to design databases that are smarter and more scalable.
Understanding Data Modeling and Entities
Identifying Core Data Entities in Your Application
The step one would take in formulating a design model of a database schema would be identifying the primary data entities that the application will manage. In a blogging platform, for instance, the data entities could be Users, Posts, Comments and Categories. Each of these entities is to form a table in the database. To define an entity, you have to understand the nature of the information it carries and, also, understand how it relates to other entities. To this effect, ask yourself, what are actual objects in my application? What attributes or fields describe each of these objects? What is this data meant for or its main purpose?
Answering such questions will begin to form an mental picture of the data structure for your application. Next useful step is to create an Entity-Relationship Diagram, so you can visualize the entities and the relationships between them. This will highlight how tables should relate to each other by means of foreign keys and which fields should be unique or indexed. At this time, you have to achieve a balance between abstraction and real-world requirements. Avoid making the design overly complex with entities or data fields that will not be used. Work with the minimum required, and build outward as necessitated by features. Such an approach keeps things simple, clear, and maintainable.
Normalization and Reducing Redundancy
With your core entities defined, it is time to normalize your collected data. Normalization, as one can guess, is meant to minimize redundancy and dependency through the efficient organization of fields into tables and the relationships between those tables. In actual practice, this means breaking relatively large tables into smaller tables and establishing their association to ensure that ‘one fact’ is kept at one place for each piece of data. Normalization usually occurs in steps, referred to by the levels of normal forms: the First Normal Form (1NF), the Second Normal Form (2NF), and the Third Normal Form (3NF), which for the most part are the ones applied in actual real-world development.
For example, you might have a table holding order information that has customer names and addresses. If a customer buys several times, he/she will have all those details repeated in each order row, thus creating redundancy. By creating a separate Customers table and linking it to the Orders table with a customer_id foreign key, you eradicate duplication, while changes like a new address become easier and less prone to errors. While normalization pushes for a clean and optimized schema, too much normalization can degrade performance for applications with heavy reads. Therefore, a balance has to exist somewhere in between reducing redundancy and maintaining query performance. As your database grows, you can, of course, denormalize or apply caching strategies selectively to optimize speed without compromising integrity.
Defining Relationships Between Tables
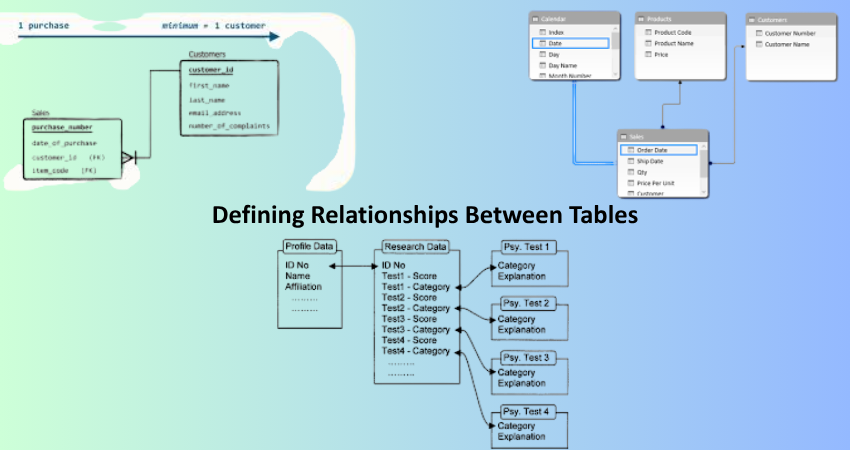
One-to-One, One-to-Many, and Many-to-Many Relationships
Building the proper relationship between tables is one of the basic principles of schema design. From the perspective of relational databases, the three types of relationships that rule for schema design are one-to-one, one-to-many, and many-to-many. Each has its applications and consequences structurally. In a one-to-one relationship, a row in one table is associated with one and only one row in another table. This configuration is very often used to partition optional or sensitive information into a separate table, such as by having user authentication credentials in a separate table than the main user profile.
A one-to-many relationship is kind of everywhere and might be the backbone of most web applications. This structure means that one record from a parent table can connect with many records from a child table. In this case, for example, there will be a User table, and there will be Posts entries that can connect. Then the Posts table will have a foreign key pointing back to the User table. Then there are many-to-many relationships coming into play when several records in one table relate to records in another. A join table typically implements it. Students might enroll in several courses and several courses might have several students attending. A join table like Enrollments with the fields student_id and course_id would manage that type of relationship very effectively.
Foreign Keys and Referential Integrity
The role of foreign keys in ensuring such relations is crucial. A foreign key, therefore, is a field (or collection of fields) in one table that uniquely identifies a row of another table, thereby establishing a link between them. A foreign key maintains referential integrity, which means that any relationship between records remain valid. For example, try to insert a comment into the database with a user_id that does not exist in the Users table, and the database will give an error assuming the proper foreign key constraints were set.
Referential integrity ensures that your data remain consistent and accurately reflect the intended relationship between tables. Enabling cascading (ON DELETE CASCADE or ON UPDATE CASCADE) will automate things like cascading delete of all posts when a user is gone. However, these Cascade options have to be used with great caution to avoid unforeseen impacts if not planned properly. Therefore, foreign keys enable you to document your thoughts for others, thus aiding the future developer to understand the data structure that is being deployed. In short, using foreign keys to maintain relationships is not only a good habit; it’s an absolute necessity if databases are to survive and remain reliable in time.
Crafting Effective Table Structures
Choosing the Right Data Types and Constraints
Choosing the right data types for each column is one of the very first things in schema design. The right types enable high data integrity, very efficient storage, and excellent query performance. For example, INTEGER is the appropriate type for numerical IDs; VARCHAR is suitable for text fields; DATE or TIMESTAMP is appropriate for date values. That way the database knows what each field is about. Avoid using overly generic types, such as TEXT or BLOB, unless absolutely necessary since these bloat storage and reduce indexing efficiency.
Beyond data types, constraints are rules that enforce data accuracy in other dimensions. Each row in a table is uniquely identifiable with a primary key. Unique constraints are used to avoid having duplicate values in columns that need to have unique data, such as an email address. Not null constraints ensure that the essential fields are not left blank. Default values and check constraints are other forms of additional control. These establish for data what can be entered. Additionally, the earlier the thought about types and constraints, the stronger and easier to query the schema will become with less opportunity for user error or inconsistent data entry.
Indexing for Performance Optimization
Indexes are yet another aspect of using the power of schema design. It dramatically increases the speed of data retrieval. An index is something like the road map of the database engine for getting towards the data without scanning the tables completely. Apart from the primary key indexes which are created automatically, there are options to create other indexes on frequently used fields like email, username, or created_at timestamps, which are used in many queries. With proper use of them, indexes can reduce time taken in queries and add to user experience, mainly in a high-frequency web application.
However, it comes with cost; for example, extra overhead during inserts and updates because the index is to be maintained updated, and too many indexes take unnecessary space in terms of disk storage. That is why indexing should be determined according to real query patterns and not at random. Monitoring tools and query analysers would help to find slow queries that would recommend good indexing. Composite indexes – that is, multiple-column indexes – could also improve complex query optimization but should be designed according to how users think those columns would be filtered and sorted in real life. In short, wise indexing means the ability to sustain performance as an application scales.
Schema Evolution and Maintenance

Planning for Scalability and Future Growth
Schema design is never an event in itself, but rather an ongoing process. As your application matures and user requirements begin to shift, your database schema should be able to follow suit. Since part of planning for scalability involves foreseeing new features, increased data volume, or additional integrations in the future, it is important to include options in your schema to cater to these possibilities. Choosing UUIDs over auto-increment integers for primary keys could perhaps be a scalable option for distributed systems. Additionally, keeping your tables normalized in the beginning means that they will be much easier to extend later on without breaking any existing logic.
Besides, horizontal and vertical scaling must be designed. It could also involve database partitioning, archiving of obsolete data, and read-replicas. Monitoring database performance and gathering metrics help in making decisions on how the schema could evolve and when. Documentation has another very important role. The more detailed schema documents and ERDs are, along with version control of schema changes (for example, using Liquibase or Flyway), the better collaboration and safer updates a development team will forge. A well-designed schema meets not only the needs of a current application but is elastic enough to grow with it.
Handling Migrations and Data Integrity
Migrations can allow new changes to be added, such as new columns or new data types or refactoring of table structures. A migration is a collection of operations that changes the state of the database from one version to another with the assurance that no data will be lost nor functionality impaired. Performing migrations via version-controlled tools ensures that every change is properly documented, can be rolled back, and consistent all through the development, staging, and production environments. This greatly helps in preventing “it works on my machine” scenarios and, consequently, enhances team collaboration.
The safeguarding of data integrity in any migration requires its own series of planning and testing. If a column were to be deleted, that column should not be present anywhere in any query or application logic. Consider how changing data types may affect records that already exist. For major changes, backing up the database is always advisable. If possible, perform migrations during low traffic or employ rolling deployments to minimize the number of users affected at the time. Testing on staging environments that mirror production ensures a smoother transition. By being methodical about migration and very careful about maintaining integrity, developers can carry out their evolution of schemas safely while not compromising reliability or user experience.
Conclusion
Database schema design is a prerequisite for web developers trying to create apps with extensibility, performance, and maintainability. From the moment to identify data entities and define relationships; from applying normalization and setting constraints to perform self-migrations; each decision carries evident effects relating to coming efficiency and stability of your backend infrastructure. Well-thought schema design minimizes data redundancy, increases query speeds, and supports its future growth without bringing complexity.
As web applications become increasingly dynamic with data, developers who pay serious attention to schema design may have the better end of the stick when demands arise for user needs and stakeholder demands as well. A properly structured schema is not simply a technical asset; it is actually a foundation for everything else to come business logic, UI/UX flow, and what follows after that such as data analytics. Once you master the set basics of database schema design side and add any best practices you have picked up along the way to your workflow, the first foundations are laid for future development projects that should stand the test of time.